구글이 요약한 LlamaFactorry와 이것을 이용한 LoRA 학습 방법의 특징 및 장점

LlamaFactory란 무엇인가요?
LlamaFactory는 대규모 언어 모델(LLM), 특히 Llama 계열 모델을 **쉽고 효율적으로 미세 조정(fine-tuning)**할 수 있도록 도와주는 **오픈소스 프레임워크(툴킷)**입니다. 복잡한 코딩 없이 웹 UI나 간단한 명령어를 통해 다양한 최신 LLM(Llama, Mistral, Qwen, Gemma 등)을 학습시킬 수 있다는 장점이 있습니다.
주요 특징:
- 사용 편의성: 직관적인 웹 UI를 제공하여 모델 선택, 데이터셋 설정, 학습 파라미터 조정 등을 쉽게 할 수 있습니다. 코딩 경험이 적은 사용자도 비교적 쉽게 LLM 튜닝을 시작할 수 있습니다.
- 다양한 학습 방법 지원:
- 전체 미세 조정 (Full Fine-tuning): 모델의 모든 파라미터를 학습시키는 전통적인 방식입니다.
- PEFT (Parameter-Efficient Fine-Tuning): 적은 파라미터만 학습시켜 효율성을 높이는 기법들을 지원합니다. LoRA가 대표적이며, QLoRA (Quantized LoRA), AdaLoRA 등 다양한 변형 기법도 지원합니다.
- 다양한 모델 및 데이터셋 지원: Hugging Face 등에서 제공하는 인기 있는 오픈소스 LLM과 다양한 형식의 데이터셋(Alpaca, ShareGPT 등)을 쉽게 사용할 수 있습니다.
- 효율성: LoRA, QLoRA 등의 기법을 통해 적은 GPU 메모리(VRAM)로도 비교적 큰 모델을 학습시킬 수 있습니다.
- 통합 환경: 데이터 전처리, 학습, 평가, 모델 병합(merging) 등의 과정을 통합적으로 지원합니다.
쉽게 말해, LlamaFactory는 LLM 튜닝을 위한 편리한 공장(Factory) 같은 역할을 한다고 생각하시면 됩니다. 필요한 부품(모델, 데이터)과 설정(학습 방법, 파라미터)을 입력하면 원하는 결과(튜닝된 모델 또는 LoRA 어댑터)를 만들어주는 도구입니다.
LlamaFactory로 LoRA 학습하는 방법
LoRA(Low-Rank Adaptation)는 LLM의 모든 가중치를 업데이트하는 대신, 기존 가중치는 그대로 두고 **작은 규모의 추가적인 가중치(어댑터)**만 학습시키는 방법입니다. 이를 통해 훨씬 적은 계산 자원과 시간으로 모델을 특정 작업에 맞게 미세 조정할 수 있습니다.
LlamaFactory를 사용하여 LoRA 학습을 진행하는 일반적인 단계는 다음과 같습니다 (주로 웹 UI 기준):
- LlamaFactory 설치 및 실행:
- GitHub 저장소를 클론(git clone)하고 필요한 라이브러리를 설치(pip install -r requirements.txt)합니다.
- 웹 UI를 실행합니다 (CUDA_VISIBLE_DEVICES=0 python src/train_web.py 와 같은 명령 사용).
- 모델 선택 (Model):
- 웹 UI 상단에서 학습시킬 **기반 모델(Base Model)**을 선택합니다. (예: meta-llama/Llama-3-8B-Instruct, mistralai/Mistral-7B-v0.1 등)
- Hugging Face 모델 경로를 직접 입력하거나 드롭다운 메뉴에서 선택할 수 있습니다.
- 학습 방법 선택 (Method):
- Fine-tuning 방법으로 **lora**를 선택합니다.
- 메모리를 더 절약하고 싶다면 qlora (4bit/8bit 양자화 + LoRA)를 선택할 수도 있습니다.
- 데이터셋 선택 (Dataset):
- 학습에 사용할 데이터셋을 선택합니다.
- LlamaFactory가 기본적으로 지원하는 데이터셋(예: alpaca_gpt4_en)을 선택하거나,
- 자신이 준비한 커스텀 데이터셋 파일(주로 JSON, JSONL 형식)의 경로를 지정합니다. (데이터 형식은 보통 instruction, input, output 구조를 따릅니다.)
- 필요하다면 데이터 미리보기(Preview) 기능으로 형식이 맞는지 확인할 수 있습니다.
- LoRA 하이퍼파라미터 설정 (Hyperparameters):
- LoRA rank (r): LoRA 어댑터 행렬의 랭크(차원)를 설정합니다. 값이 클수록 더 많은 파라미터를 학습하지만, 메모리 사용량과 계산량이 늘어납니다. 보통 8, 16, 32, 64 등이 사용됩니다.
- LoRA alpha: LoRA 결과에 적용되는 스케일링 값입니다. 보통 rank 값과 같거나 2배로 설정합니다.
- LoRA target modules: LoRA를 적용할 모델 내부의 레이어(모듈)를 지정합니다. 보통 Attention 레이어의 q_proj, v_proj 등이 대상이 되며, LlamaFactory가 모델에 맞는 기본값을 제안해 줍니다. (예: all, q_proj,v_proj)
- Learning rate: 학습률을 설정합니다. LoRA는 보통 Full Fine-tuning보다 약간 높은 학습률을 사용하기도 합니다.
- Epochs: 전체 데이터셋을 몇 번 반복 학습할지 설정합니다.
- Batch size: 한 번의 스텝에서 처리할 데이터 샘플 수를 설정합니다. GPU 메모리에 맞춰 조절해야 합니다.
- Output directory: 학습된 LoRA 어댑터 파일이 저장될 경로를 지정합니다.
- (QLoRA 사용 시) Quantization bit: 양자화 비트 수(4 또는 8)를 선택합니다.
- 학습 시작 (Start):
- 설정이 완료되면 "Start" 또는 "Run" 버튼을 클릭하여 학습을 시작합니다.
- 웹 UI나 터미널에서 학습 진행 상황(Loss, 진행률 등)을 모니터링할 수 있습니다.
- 결과 확인:
- 학습이 완료되면 지정한 Output directory에 LoRA 어댑터 파일(보통 adapter_model.bin 또는 PyTorch/Safetensors 형식 파일)과 설정 파일(adapter_config.json) 등이 생성됩니다.
학습된 LoRA 어댑터 사용:
이렇게 학습된 LoRA 어댑터는 원본 기반 모델에 "덧씌워서" 사용합니다. 추론(inference) 시에는 원본 모델을 로드한 후, 저장된 LoRA 어댑터 가중치를 로드하여 적용하면 됩니다. LlamaFactory는 학습된 어댑터를 병합(merge)하여 단일 모델로 만들거나, 추론 시 동적으로 로드하는 기능도 제공합니다.
요약:
LlamaFactory는 LoRA와 같은 효율적인 미세 조정 기법을 웹 UI를 통해 매우 쉽게 사용할 수 있게 해주는 강력한 도구입니다. 복잡한 설정이나 코드 구현 없이도 원하는 모델과 데이터를 가지고 빠르게 LLM을 특정 목적에 맞게 튜닝할 수 있습니다.
LlamaFactory를 uv로 관리하고 실행하는 방법 (단계별 가이드)
uv는 Rust로 작성된 매우 빠른 Python 패키지 설치 및 관리 도구입니다. 기존의 pip 및 venv보다 훨씬 빠른 속도를 제공하여 개발 환경 설정을 효율적으로 만들어 줍니다.
사전 요구 사항:
- Python: 최신 버전의 Python 3.x 설치 (LlamaFactory가 지원하는 버전 확인 권장, 보통 3.9 이상)
- Git: 코드를 다운로드하기 위해 Git 설치
- NVIDIA GPU 및 드라이버: LLM 학습에는 일반적으로 NVIDIA GPU가 필요합니다. 최신 드라이버를 설치하세요.
- CUDA Toolkit: 사용 중인 GPU 드라이버 및 PyTorch와 호환되는 CUDA Toolkit 버전 설치 (PyTorch 설치 시 자동으로 설치되는 경우도 있으나, 명시적 설치가 필요할 수 있음)
단계별 설정 및 실행:
1단계: uv 설치
먼저 시스템에 uv를 설치합니다. uv 공식 문서에서 권장하는 방법은 다음과 같습니다.
- macOS / Linux:
curl -LsSf https://astral.sh/uv/install.sh | sh - Windows (PowerShell):
powershell -c "irm https://astral.sh/uv/install.ps1 | iex"설치가 완료되면 터미널(명령 프롬프트)을 새로 열고 다음 명령어로 설치를 확인합니다.
uv --version2단계: LlamaFactory 저장소 복제 (Clone)
LlamaFactory 코드를 로컬 컴퓨터로 가져옵니다. 원하는 디렉토리에서 다음 명령어를 실행하세요.
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
3단계: uv를 사용하여 가상 환경 생성
프로젝트의 의존성을 시스템의 다른 Python 패키지와 격리하기 위해 가상 환경을 만듭니다. uv를 사용하면 매우 빠르게 생성할 수 있습니다.
# 설치된 Python 버젼으로 셋팅
uv venv
# Python 3.11 버젼 명시
uv venv --python=python3.11이 명령은 현재 디렉토리(.) 안에 .venv라는 이름의 가상 환경을 생성합니다. (다른 이름을 원하면 uv venv <이름> 형식으로 지정 가능)
4단계: 가상 환경 활성화
생성된 가상 환경을 활성화하여 이후 설치되는 패키지들이 이 환경 안에 설치되도록 합니다.
- macOS / Linux:
-
source .venv/bin/activate - Windows (CMD):
-
.\.venv\Scripts\activate.bat - Windows (PowerShell):
-
.\.venv\Scripts\Activate.ps1
활성화되면 터미널 프롬프트 앞에 (.venv)와 같이 가상 환경 이름이 표시됩니다.
5단계: uv를 사용하여 의존성 패키지 설치
LlamaFactory 실행에 필요한 라이브러리들을 설치합니다. uv는 pip install과 유사한 명령어를 사용하며, requirements.txt 파일을 읽어 필요한 패키지들을 설치합니다.
- 중요: PyTorch 설치 (CUDA 버전 확인)
LLM 학습에는 PyTorch가 필수적이며, 사용 중인 CUDA 버전에 맞는 PyTorch를 설치해야 합니다. 먼저 PyTorch 공식 웹사이트를 방문하여 자신의 환경(OS, CUDA 버전 등)에 맞는 PyTorch 설치 명령어를 확인하세요. - nvidia-smi 로 CUDA 버젼확인

nvidia-smi 로 CUDA 버젼확인 -
# 예시: CUDA 12.1 용 PyTorch 설치 (실제 명령어는 PyTorch 웹사이트 참고) uv pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121 - 예를 들어, CUDA 12.1 환경이라면 다음과 유사한 명령어를 uv pip install로 실행합니다 (명령어는 PyTorch 웹사이트에서 복사하세요):
- LlamaFactory 요구사항 설치:
PyTorch가 성공적으로 설치되었다면, LlamaFactory의 나머지 요구사항을 설치합니다.uv는 pip보다 훨씬 빠르게 패키지들을 다운로드하고 설치할 것입니다.- 참고: 만약 특정 기능(예: Flash Attention 2, DeepSpeed 등)을 사용하려면 해당 기능에 맞는 requirements_*.txt 파일을 추가로 설치해야 할 수 있습니다. (예: uv pip install -r requirements_pt.txt ) 필요에 따라 LlamaFactory 문서를 참고하세요.
- 참고: 일부 패키지 설치 시 빌드 도구(gcc, C++ 컴파일러 등)가 필요할 수 있습니다. 설치 중 오류가 발생하면 관련 빌드 도구를 시스템에 설치해야 할 수 있습니다. (예: Ubuntu/Debian: sudo apt install build-essential)
uv pip install -r requirements.txt
6단계: LlamaFactory 웹 UI 실행
이제 모든 준비가 끝났습니다. LlamaFactory의 웹 기반 인터페이스를 실행합니다.
# 사용할 GPU 지정 (0번 GPU만 사용하려면)
export CUDA_VISIBLE_DEVICES=0
# 웹 UI 실행 (Windows에서는 export 대신 set 사용: set CUDA_VISIBLE_DEVICES=0)
python src/webui.py- CUDA_VISIBLE_DEVICES=0: 사용하려는 NVIDIA GPU의 번호를 지정합니다. 여러 개가 있다면 0,1 등으로 지정할 수 있습니다.
- python src/webui.py: LlamaFactory 웹 서버를 실행하는 명령입니다.
터미널에 웹 서버가 실행 중이라는 메시지와 함께 로컬 주소(보통 http://127.0.0.1:7860 또는 http://localhost:7860)가 나타납니다.
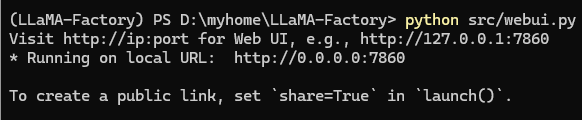
7단계: 웹 브라우저에서 접속
웹 브라우저를 열고 터미널에 표시된 주소 (예: http://127.0.0.1:7860) 로 접속합니다. LlamaFactory 웹 UI가 나타나면 성공입니다!
이제 웹 UI를 통해 모델, 데이터셋, 학습 방법(LoRA 등), 하이퍼파라미터 등을 설정하고 LLM 미세 조정을 시작할 수 있습니다.

추가 팁:
- 종료: 웹 UI 사용이 끝나면 터미널에서 Ctrl + C를 눌러 서버를 중지합니다.
- 가상 환경 비활성화: 작업이 끝나면 터미널에서 deactivate 명령어를 입력하여 가상 환경을 빠져나옵니다.
- 나중에 다시 실행: 다시 LlamaFactory를 사용하려면 LLaMA-Factory 디렉토리로 이동한 후 4단계 (가상 환경 활성화) 부터 다시 진행하면 됩니다. (패키지는 이미 설치되어 있으므로 5단계는 건너뛰고 6단계 실행)
- 환경 제거: 만약 프로젝트 환경을 완전히 제거하고 싶다면, 비활성화된 상태에서 .venv 디렉토리를 삭제하면 됩니다 (rm -rf .venv 또는 파일 탐색기에서 삭제).
다른글들:
2025.03.11 - [Python] - 파이썬으로 초간단하게 웹서버 만들기
파이썬으로 초간단하게 웹서버 만들기
파이썬으로 초간단하게 웹서버를 만들수 있습니다. python -m http.server 8000 --bind 0.0.0.0 --directory d:\work 파이썬이 설치 되어 있다면 커맨드창에서 위 명령어를 입력하면 아무 pc에서나 http://[당신
dtbb.tistory.com
2024.05.01 - [Python] - 주피터 노트북에 내가 만든 가상환경 나오게 하는 방법
주피터 노트북에 내가 만든 가상환경 나오게 하는 방법
주피터 노트북(Jupyter Notebook)에서 내가 만든 가상환경을 이용해서 개발하려고 하는데 기본적으로는 안보입니다. 특별하게 등록을 해주어야 보입니다. 주피터 노트북에 내가 만든 가상환
dtbb.tistory.com
2024.08.27 - [AI] - LLM 이용시 효과적인 프롬프팅 방법 (f.당근)
LLM 이용시 효과적인 프롬프팅 방법 (f.당근)
LLM 을 이용시 프롬프트에 따라 답변의 질이 많이 달라진다."LLM을 프로덕션에 적용하며 배운 것들 | 당근 ML 밋업 1회" 에서 효과적인 프롬프팅 방법에 대해 다루고 있어서 가지고 왔다.텍스트로
dtbb.tistory.com
2024.03.21 - [Python] - 미니콘다(miniconda) 가상환경 list, 생성, 삭제, 활성화, 비활성화 방법
미니콘다(miniconda) 가상환경 list, 생성, 삭제, 활성화, 비활성화 방법
미니콘다(miniconda)에서 가상환경 list를 확인하고, 생성, 삭제, 활성화, 비활성화 방법을 알아보자 참조 사이트 : https://bizzengine.tistory.com/131 가상환경의 경로를 바꾸려할때는 다음 글 참조 : 2024
dtbb.tistory.com
'AI' 카테고리의 다른 글
| 💼 AI 전문가의 필수템! Claude Max 요금제 비교 분석 (0) | 2025.04.17 |
|---|---|
| ChatGPT 4o로 만화 그리기 (0) | 2025.03.28 |
| Claude Code와 Think 모드: AI 개발 도구의 혁신적 사고 능력 (0) | 2025.03.24 |
| 클로드에서 웹 검색 이용하기(f. playwright-mcp-server) (2) | 2025.03.21 |
| 어텐션 메커니즘 쉽고 명확하게 이해하기 (f. 트랜스포머의 핵심) (1) | 2024.09.13 |



